
Nearly 20% of a knowledge worker’s time is wasted every week searching for lost information or redoing incomplete documentation.
Every week, that’s an entire day spent recovering from preventable inefficiencies. The global AI voice recognition market is on track to surpass $50 billion by 2030, and it’s no coincidence. Businesses are waking up to a massive, often-overlooked operational problem.
Meetings often run long, notes get misplaced, and essential details are easily forgotten. In fields like healthcare, law, and customer service, even one missed word can lead to serious issues, like compliance violations, misdiagnoses, or losing a client.
Despite technological advancements, many organizations still depend on manual note-taking or delayed transcription. These methods take time and are often inaccurate, leading to errors and inefficiencies.
And it’s costing us. And the problem is only growing.
This is where AI Automatic Speech Recognition (ASR) is stepping in, not just as a tool for convenience, but as a solution to an urgent operational need.
AI Automatic Speech Recognition uses machine learning and natural language processing to transform spoken words into text in real time. Unlike regular systems, AI-powered ASR understands context, adapts to industry-specific vocabulary, and handles noisy environments precisely. It helps in turning conversations into structured, actionable data.
In this blog, we’ll explain how AI Automatic Speech Recognition works, where it’s being used, and why it’s becoming indispensable for businesses looking to scale, comply, and communicate better.
ASR vs. Voice Recognition: What’s the Real Difference?
Automatic Speech Recognition (ASR) is a technology that enables computers to convert spoken language into written text. It processes audio inputs, identifies speech patterns, and transcribes spoken words into text. ASR systems utilize algorithms and machine learning techniques to analyze audio signals and transcribe them into text.
While ASR and voice recognition both deal with audio inputs, they serve different purposes:
ASR (Automatic Speech Recognition) focuses on transcribing spoken language into text, aiming for high accuracy and contextual understanding.
In contrast, voice recognition primarily focuses on identifying and verifying a speaker’s identity based on their unique voice characteristics. ASR is about understanding and transcribing what is being said, whereas voice recognition is about identifying who is speaking.
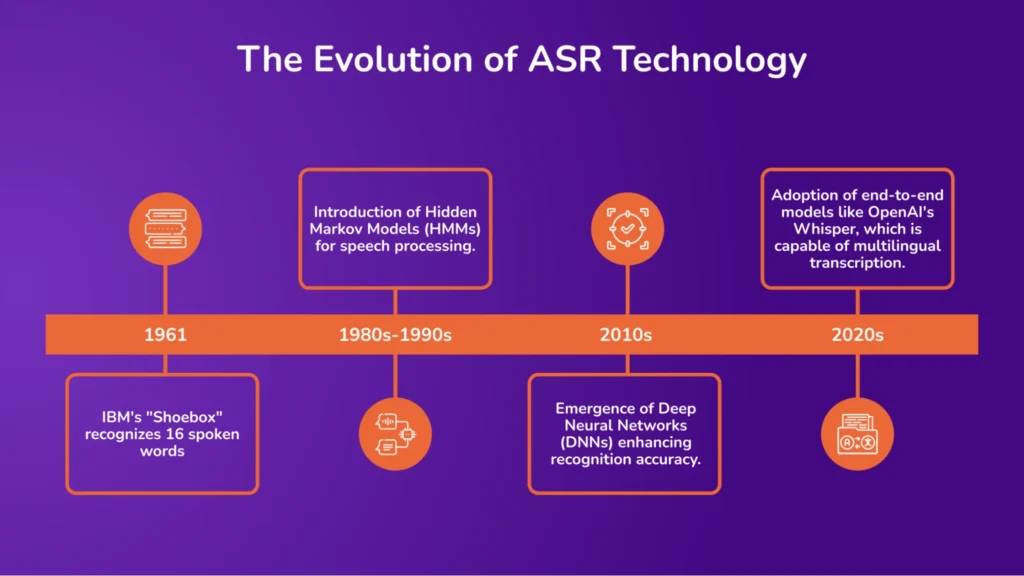
How Does AI Automatic Speech Recognition Work? A Technical Breakdown
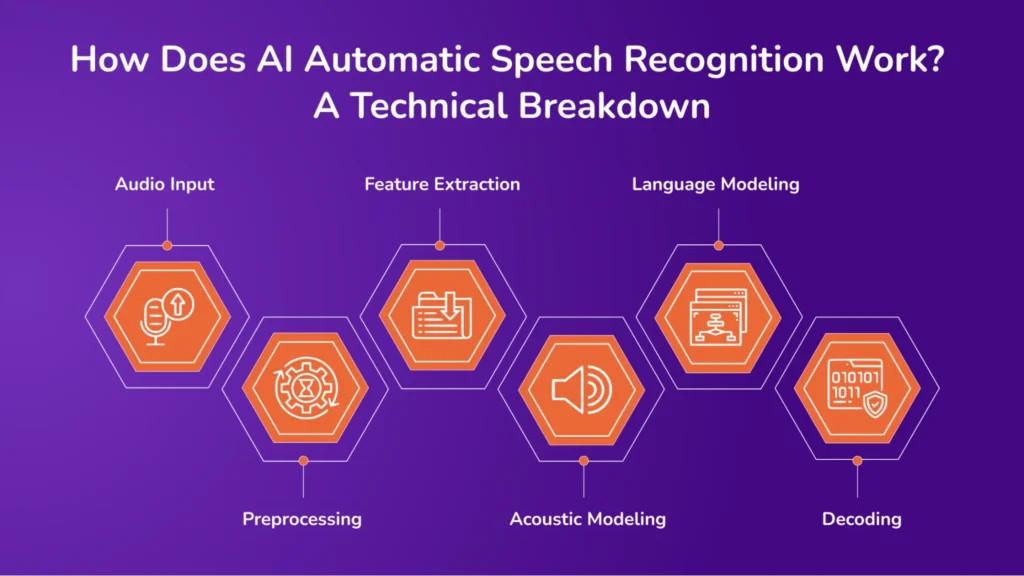
Here’s a closer look at the process behind AI automatic speech recognition, breaking down each step of turning spoken language into accurate text.
1. Audio Input
The process begins with capturing spoken language through a microphone or recording device. The analog audio signal is then digitized into a format suitable for computational processing. This digital representation serves as the foundation for subsequent analysis.
2. Preprocessing
Preprocessing aims to enhance the quality of the audio signal and prepare it for feature extraction. Essential steps include:
- Noise Reduction: Techniques like spectral subtraction or adaptive filtering are applied to minimize background noise and improve signal clarity. blog.milvus.io
- Normalization: Adjusting the audio signal’s amplitude consistently ensures uniformity across different recordings.
- Silence Removal: Eliminating periods of silence or irrelevant sounds helps focus the analysis on meaningful speech segments.
3. Feature Extraction
In this phase, the preprocessed audio signal is transformed into representative features that capture essential speech characteristics. Common techniques include:
- Mel-Frequency Cepstral Coefficients (MFCCs): These coefficients model the human ear’s perception of sound, emphasizing frequencies most significant for speech recognition.
- Spectrograms: Visual representations of the frequency spectrum over time, providing insights into the temporal and spectral properties of the audio.
These features serve as inputs to the subsequent modeling stages.
4. Acoustic Modeling
Acoustic models establish the relationship between a language’s extracted features and phonetic units (phonemes). Two prevalent approaches are: Mael Fabie.n
- Hidden Markov Models (HMMs) are statistical models that represent the sequence of phonemes and their temporal variations. They are effective in modeling time-dependent processes like speech.
- Deep Neural Networks (DNNs): These models learn complex patterns in the data, capturing non-linear relationships between features and phonemes. DNNs have significantly improved recognition accuracy in recent years.
Acoustic models play a crucial role in decoding speech by modeling the probabilistic relationship between audio features and phonemes.
5. Language Modeling
Language models predict the likelihood of word sequences, aiding in selecting the most probable transcription. Common types include:
- N-gram Models: These models estimate the probability of a word based on the preceding (n-1) words, capturing local context.
- Neural Language Models: These models utilize architectures like Recurrent Neural Networks (RNNs) or Transformers to capture long-range dependencies and complex linguistic patterns.
Integrating language models helps resolve ambiguities and improves the grammatical correctness of the transcribed text.
6. Decoding
The decoding process combines information from the acoustic and language models to generate the final transcription. Key components include:
- Pronunciation Dictionary: A lexicon mapping words to their phonetic representations, facilitating the connection between acoustic signals and textual output.
- Search Algorithms: Techniques like the Viterbi algorithm are employed to find the most probable sequence of words given the probabilities of the acoustic and language models.
The decoder outputs the text that best matches the spoken input, considering acoustic evidence and linguistic context.
Modern Architectures in AI Automatic Speech Recognition: End-to-End Models
Conventional ASR systems involve separate components for acoustic modeling, language modeling, and decoding. In contrast, end-to-end models integrate these components into a single neural network architecture, simplifying the pipeline and often improving performance.
Recurrent Neural Networks (RNNs)
RNNs, including variants like Long Short-Term Memory (LSTM) networks, are made to handle sequential data. In ASR, RNNs process the sequence of audio features and generate corresponding text outputs. They can model temporal dependencies in speech but may struggle with long sequences due to issues like vanishing gradients.
Transformers
Transformers utilize self-attention mechanisms to capture relationships between all elements in a sequence, regardless of distance. This architecture allows for parallel processing and has shown superior performance in ASR tasks. Transformers can model long-range dependencies more effectively than RNNs, making them well-suited for complex speech recognition scenarios.
End-to-end models, particularly those based on Transformers, have become the state-of-the-art in ASR, offering streamlined architectures and improved accuracy.
Essential Features of AI Automatic Speech Recognition Systems
Below are the key features that make AI automatic speech recognition systems effective, enabling them to convert speech into text in various applications accurately
1. Language Weighting
Language weighting enhances the recognition of specific words or phrases by assigning them higher importance within the language model. This is particularly useful for frequently used terms, such as product names or industry-specific jargon, ensuring they are accurately recognized during transcription.
2. Speaker Labeling
Speaker labeling involves identifying and tagging individual speakers in multi-participant conversations. This feature enables the system to attribute each speech segment to the correct speaker, facilitating more precise and more organized transcriptions, especially in meetings or interviews.
3. Acoustic Training
Acoustic training allows the ASR system to adapt to specific environmental conditions and speaker characteristics. The system can maintain high accuracy even in noisy environments or with diverse speaking styles by learning from various acoustic settings and speech patterns.
4. Profanity Filtering
Profanity filtering enables the system to detect and manage inappropriate language within transcriptions. This feature is essential for maintaining professionalism and adhering to content guidelines in various applications.
Training Methodologies for Automatic Speech Recognition Systems
Here is the list of essential training methodologies used to develop and enhance automatic speech recognition systems:
1. Supervised Learning
Supervised learning is the foundational approach for training ASR systems. It involves training models on large, labeled datasets where each audio clip is paired with its corresponding transcription. This method enables the model to learn the direct mapping between audio features and textual representations.
Supervised learning for Automatic Speech Recognition (ASR) requires extensive labeled datasets, which can be resource-intensive to create. This approach offers high accuracy in transcription because it directly links audio features with their corresponding transcriptions. It is particularly effective in scenarios with large amounts of labeled data, such as in English ASR systems.
However, there are some challenges. Scalability is a significant concern, as collecting and annotating large datasets can be time-consuming and costly. Additionally, models trained on specific datasets may struggle to generalize effectively to different accents, dialects, or noisy environments, limiting their adaptability in diverse real-world applications.
2. Weakly-Supervised Learning
Weakly supervised learning combines a small labeled data set with a larger set of unlabeled data. This approach aims to utilize the abundance of unlabeled data to improve model performance while reducing the reliance on manually annotated datasets.
Weakly-supervised learning combines a smaller set of labeled data with a larger set of unlabeled data, making it less dependent on large annotated datasets. This cost-effective approach reduces the time and financial resources required for data labeling. It is particularly effective in low-resource languages or specialized domains where labeled data is scarce.
The method requires sophisticated algorithms to use the unlabeled data effectively. Additionally, the model’s performance can vary depending on the quality and quantity of the unlabeled data, leading to variability in results.
3. Transfer Learning
Transfer learning involves taking a pre-trained model, typically trained on a large, general dataset, and fine-tuning it on a smaller, domain-specific dataset. This approach allows the model to utilize knowledge gained from one task to improve performance on another, related task.
Transfer learning allows models to apply learned features from one domain to another, enhancing performance without starting from scratch. This resource-efficient method reduces the need for large amounts of domain-specific data. It is beneficial when collecting large labeled datasets, such as in specialized medical or legal transcription, is impractical.
However, transfer learning comes with its own set of challenges. Performance may degrade if the source and target domains significantly differ due to domain mismatch. Additionally, careful fine-tuning is required to adapt the pre-trained model effectively to the new domain, ensuring optimal performance.
4. Multi-Task Learning
Multi-task learning involves training a single model to perform multiple related tasks simultaneously. In the context of ASR, this could mean teaching a model to perform speech recognition alongside tasks like speaker identification or emotion detection.
Multi-task learning enables a model to learn multiple tasks simultaneously, allowing it to develop shared representations that improve performance across all functions. This method enhances efficiency by allowing the model to generalize, learn from related tasks, and improve performance. It is especially beneficial in applications that require multiple outputs from a single input, such as virtual assistants.
Task interference can occur when different tasks conflict, which may result in suboptimal performance on individual tasks. Additionally, designing and training multi-task models can be more complex than single-task models, requiring careful planning and resources.
Real-World Applications of Automatic Speech Recognition (ASR)
Below are some use cases of AI Automatic Speech Recognition (ASR), showcasing how this technology is transforming industries across the globe.
1. Healthcare
In the healthcare sector, ASR technology is employed to transcribe doctor-patient interactions, aiding in creating electronic health records (EHRs). This automation enhances documentation accuracy and allows healthcare professionals to focus more on patient care.
For instance, Brigham and Women’s Hospital conducted a study revealing that physicians using speech recognition produced more detailed and higher-quality notes than traditional typing methods.
2. Customer Service
ASR is integral to modern customer service operations, particularly in call centers. It enables automated call transcriptions, facilitates sentiment analysis, and ensures quality assurance.
Interactive Voice Response (IVR) systems utilize ASR to route calls efficiently and handle routine inquiries without human intervention, reducing wait times and operational costs.
3. Education
In educational settings, ASR provides real-time captions for lectures, benefiting students who are deaf or hard of hearing. It also assists in language learning by transcribing spoken language, allowing learners to improve pronunciation and comprehension.
4. Accessibility
ASR technology significantly enhances accessibility for individuals with hearing impairments by providing live captioning and transcriptions. Innovations like AI-powered signing avatars translate text into sign language, bridging communication gaps.
For example, Silence Speaks has developed avatars that convert text into British and American Sign Language, aiding over 70 million deaf or hard-of-hearing individuals worldwide.
5. Legal and Media
ASR transcribes court proceedings, depositions, and legal dictations in the legal domain, streamlining documentation processes.
In the media industry, it assists in transcribing interviews and generating subtitles for video content, enhancing accessibility and content management. These applications improve efficiency and ensure accurate record-keeping.
Avahi AI Live Transcription: Streamlining Real-Time Communication and Record-Keeping
Avahi AI platform offers a live transcription feature to streamline documentation and communication processes across various industries. This tool allows organizations to capture, transcribe, and analyze spoken content in real time, enhancing efficiency and accuracy in record-keeping and customer interactions.
How It Works:

Avahi AI’s Live Transcription utilizes advanced Automatic Speech Recognition (ASR) technology to convert spoken language into written text in real-time. The process involves several essential steps:
1. Audio Capture: The system captures audio input from various sources, such as live conversations, meetings, or uploaded recordings.
2. Speech Processing: Utilizing sophisticated algorithms, the audio is analyzed to identify linguistic patterns and nuances.
3. Transcription Generation: The processed audio is then transcribed into text, maintaining high accuracy even in complex or noisy environments.
4. Integration and Output: The transcribed text can be seamlessly integrated into existing systems, such as Electronic Health Records (EHRs), or exported for further use.
This streamlined process ensures efficient and accurate transcription suitable for various professional settings.
Applications Across Industries
Avahi AI’s Live Transcription is versatile and can be applied across multiple sectors:
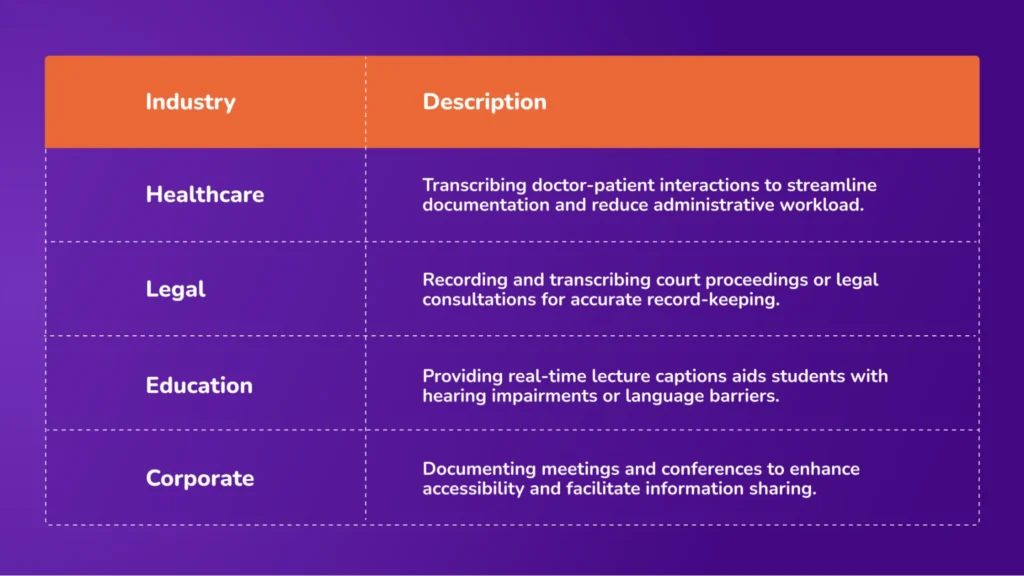
Benefits of Avahi AI’s Live Transcription Feature
1. Enhanced Efficiency
Avahi AI’s Live Transcription automates converting spoken language into written text, significantly reducing the time required for manual transcription.
This automation allows professionals to focus on core tasks, such as patient care in healthcare settings or strategic decision-making in business environments. By streamlining documentation processes, organizations can improve overall productivity and workflow efficiency.
2. Improved Accuracy
Avahi AI’s Live Transcription delivers high-precision transcriptions using advanced algorithms and machine learning techniques. The system is trained on diverse datasets, enabling it to transcribe various accents, dialects, and industry-specific terminology accurately.
This level of accuracy minimizes errors commonly associated with manual transcription, ensuring reliable documentation across different sectors.
3. Cost-Effectiveness
Avahi AI’s Live Transcription offers organizations a cost-effective solution by reducing the need for manual transcription services. Automating transcription processes lowers labor costs and minimizes the time spent on administrative tasks.
This financial efficiency allows businesses to allocate resources more effectively and invest in other critical areas of operation.
4. Enhanced Accessibility
Real-time transcription capabilities of Avahi AI’s system support inclusivity by providing immediate text versions of spoken content. This feature particularly benefits individuals with hearing impairments, enabling them to access information concurrently with their peers.
Additionally, it aids non-native speakers and others who may benefit from reading along with spoken content, thereby promoting a more inclusive environment.
Discover Avahi’s AI Platform in Action

At Avahi, we empower businesses to deploy advanced Generative AI that streamlines operations, enhances decision-making, and accelerates innovation—all with zero complexity.
As your trusted AWS Cloud Consulting Partner, we empower organizations to harness AI’s full potential while ensuring security, scalability, and compliance with industry-leading cloud solutions.
Our AI Solutions include
- AI Adoption & Integration – Utilize Amazon Bedrock and GenAI to enhance automation and decision-making.
- Custom AI Development – Build intelligent applications tailored to your business needs.
- AI Model Optimization – Seamlessly switch between AI models with automated cost, accuracy, and performance comparisons.
- AI Automation – Automate repetitive tasks and free up time for strategic growth.
- Advanced Security & AI Governance – Ensure compliance, fraud detection, and secure model deployment.
Want to unlock the power of AI with enterprise-grade security and efficiency? Get Started with Avahi’s AI Platform!
Frequently Asked Questions
1. What is AI Automatic Speech Recognition (ASR)?
AI Automatic Speech Recognition (ASR) is a technology that converts spoken language into written text using artificial intelligence and machine learning. It listens to speech through a microphone or audio file, processes the sound, and provides real-time or recorded transcriptions. ASR is used across industries to reduce manual documentation and improve communication.
2. How does AI ASR work?
AI ASR captures audio, cleans it to remove noise, and extracts key speech features. These features are then analyzed by algorithms and language models to identify and transcribe spoken words. Advanced ASR systems also understand context, accents, and technical vocabulary, delivering more accurate results.
3. What is the difference between ASR and voice recognition?
ASR (Automatic Speech Recognition) is designed to transcribe what is being said, turning speech into text. Voice recognition, on the other hand, focuses on identifying who is speaking based on voice patterns. While both work with audio, their purposes differ; ASR helps with transcription, whereas voice recognition is about speaker authentication.
4. Why is AI ASR important for businesses?
AI ASR helps businesses save time, reduce human error, and streamline operations. It automates meeting notes, call transcriptions, and documentation tasks—freeing up employees for higher-value work. Accurate transcription in regulated industries like healthcare or law helps with compliance and record-keeping.
5. Can AI ASR handle different accents or noisy environments?
Modern AI ASR systems are trained on large, diverse datasets that include different accents, dialects, and background noises. With advanced preprocessing and acoustic modeling, these systems can accurately transcribe speech even in noisy settings or when spoken by people with varied speech patterns.

